Introduction
Table of Contents
Introduction
The early twentieth century saw a dramatic change in British literature. The end of the Victorian era, with the death of Queen Victoria in 1901, symbolized for many the beginning of a new literary period, and with it came a new aesthetics. This new aesthetics distinguishes itself from those previous by means of its approach to visuality: not only did the writers of this generation write differently, but they began to see differently, as well. This dissertation investigates the changes in visuality that so strongly characterize this tumultuous time in literary history, using a blend of qualitative and quantitative methods. Modeling textual visuality using techniques from computer science, statistics, and computational linguistics, I reveal the mechanics of this turn-of-the-century explosion of ocularity, and present the circumstances, and the causal agents, of this phenomenon.
Consider, as a starting point, this passage from Jane Austen’s Pride and Prejudice, from 1813:
At length the Parsonage was discernible. The garden sloping to the road, the house standing in it, the green pales and the laurel hedge, every thing declared they were arriving. Mr. Collins and Charlotte appeared at the door, and the carriage stopped at the small gate, which led by a short gravel walk to the house, amidst the nods and smiles of the whole party. In a moment they were all out of the chaise, rejoicing at the sight of each other. Mrs. Collins welcomed her friend with the liveliest pleasure, and Elizabeth was more and more satisfied with coming, when she found herself so affectionately received. She saw instantly that her cousin’s manners were not altered by his marriage; his formal civility was just what it had been, and he detained her some minutes at the gate to hear and satisfy his enquiries after all her family. They were then, with no other delay than his pointing out the neatness of the entrance, taken into the house; and as soon as they were in the parlour, he welcomed them a second time with ostentatious formality to his humble abode, and punctually repeated all his wife’s offers of refreshment. (Austen)
This passage, one of Austen’s more descriptive paragraphs, contains concrete descriptors of people, places and things, and paints a clear tableau of the parsonage. Through the eyes of Austen’s narrator, we see a house with a garden, a hedge, a gravel walk, and a small gate; an interior parlor, where drinks are being served, and where people are nodding and smiling. Yet despite all of this, this description is heavily subordinated to the interpersonal cordialities, relations, and emotions. We see indeed that the pales are “green,” and the hedge made of laurel, but these things exist only to “declare they were arriving.” In the foreground, we see a meeting between Elizabeth and Mr. and Mrs Collins, which is described in abstract emotional terms, emphasizing “the liveliest pleasure,” in which Elizabeth is “more and more satisfied,” and feels “affectionately received.” We hear of vague “manners,” “civility,” and “enquiries after all her family,” a certain “neatness” of the house, and the “ostentatious formality” of his welcome. While we should not dismiss these abstractions as mere social drama—Austen’s famously knowing style frequently contains layers of subtexts of satire or social commentary—they nonetheless exemplify a mode which is more concerned with social experience than vision. Despite the modicum of description in this passage, we will later discover, though computational analysis, that Austen is among the least visual writers of the 19th and 20th centuries.
Now, in contrast, consider a passage from our destination, this passage from Virginia Woolf’s Jacob’s Room, from over a hundred years later, in 1922:
Mrs. Flanders, who was growing stout, sat down in the fortress and looked about her. / The entire gamut of the view’s changes should have been known to her; its winter aspect, spring, summer and autumn; how storms came up from the sea; how the moors shuddered and brightened as the clouds went over; she should have noted the red spot where the villas were building; and the criss-cross of lines where the allotments were cut; and the diamond flash of little glass houses in the sun. Or, if details like these escaped her, she might have let her fancy play upon the gold tint of the sea at sunset, and thought how it lapped in coins of gold upon the shingle. Little pleasure boats shoved out into it; the black arm of the pier hoarded it up. The whole city was pink and gold; domed; mist-wreathed; resonant; strident. Banjoes strummed; the parade smelt of tar which stuck to the heels; goats suddenly cantered their carriages through crowds. It was observed how well the Corporation had laid out the flower-beds. Sometimes a straw hat was blown away. Tulips burnt in the sun. Numbers of sponge-bag trousers were stretched in rows. Purple bonnets fringed soft, pink, querulous faces on pillows in bath chairs. Triangular hoardings were wheeled along by men in white coats. Captain George Boase had caught a monster shark. One side of the triangular hoarding said so in red, blue, and yellow letters; and each line ended with three differently coloured notes of exclamation. (Woolf)
In contrast, Woolf’s descriptive passage is thickly indulgent in its vision. We see a cornucopia of details in this Scarborough landscape, as if we are following a painter’s brush across a canvas. The villas are “red spots,” with “criss-crossed” lines; the houses appear with a “diamond flash”; the sea has a “gold tint” imaginatively literalized into “coins of gold.” We see a number of very colorful things, too: the “black arm” of the pier, the “pink and gold” city, purple bonnets, pink faces, white coats, and letters which are red, blue, and yellow. And yet, this passage, although it is still legible as a descriptive paragraph, is framed with Mrs. Flanders’s mental and emotional state. She has just been thinking about her deceased husband, and wondering, “had he, then, been nothing?” since he had “only sat behind an office window for three months.” The passage of time, then, is present here in a way that is impossible in a landscape painting: Mrs. Flanders sees the “winter aspect” of the summer scene, just as with her husband. We see these details through her eyes, but also more objectively: maybe “details like these escaped her”; maybe she “might have let her fancy play.” This is a multi-sensory passage, as well: the landscape is not only painted, but strummed on a banjo, smelled in the tar, and felt in the sea mist.
I choose these two passages advisedly—Austen’s is among the least visual novels, according to the model of visuality I will soon present, and Woolf’s is among the most. The story of description, then, across the nineteenth and early twentieth centuries, is one where vision sharpens: objects become clearer, colors brighter. But how exactly do we get from point A to point B? How does description evolve, from Austen to Woolf? This is a difficult question, since chronology alone cannot account for all these differences. For one, there is a huge generic gap: Austen writes within the genre of the social drama, romance, or social satire, depending on your point of view. Woolf’s novel, however, belongs to a high modernist genre. There are also authorial styles to consider, as well as the writers’ biographies that conditioned them: Austen’s social sphere and Woolf’s Bloomsbury, with its artists and art critics. Character voices are also important variables: the differences between Austen’s narrator, aware of Elizabeth, and the free indirect discourse informed by Mrs. Flanders’s thoughts. This is where computational analysis helps. By analyzing thousands of novels and poems, computationally—many more than a single human could hope to read—we can begin to isolate historical signals, and adjust for the influence of genre, style, voice, and other factors. I argue that the largest factor of this diachronic development is visual.
The title of this dissertation, “The Eye of Modernism,” alludes to the changes in ocularities at the turn of the century: a turn towards the visual, and to the workings of the primary visual organ: the eye. First, I should explain that I mean “eye” in a more literal sense than it is usually used. Typically, “vision” is used in its metaphorical sense more than its literal sense: a vision is not a sight, that is, the result of act of seeing, but an imaginary picture, often a premonition: a mental image of something which is not real. This is more apparent in this literary period than in any other, as evident by such titles as William Butler Yeats’s A Vision and H.D.’s Notes on Thought and Vision, which deal with occult visions, rather than ocular ones. I mean vision as the act of the eye, and use the retina as my guiding metaphor. The eye’s retina is composed of two primary receptor types: cones, primarily responsible for color vision, and rods, primarily responsible for perception of shapes and objects. These I map onto my first two chapters.
In Chapter 1, the longest chapter, I discuss color, the phenomenon perceived by retinal cones. I develop a computational model of literary imagination, capable of inferring color values from color expressions, adjectives and nouns with inherent color properties, and other visual passages in text. Using this model, I study the changes in literary color over time, and find, among other trends, that there was a significant increase over the turn of the century, most notably around 1910. Pulling from a broad theoretical base, I explain this phenomenon, and complicate it, using the period’s writings in philosophy, anthropology, and literary history, among other disciplines.
In Chapter 2, I discuss shape and object vision, phenomena perceived by retinal rods. The quantitative analysis I employ here uses neural networks, running in parallel across a vast cluster of high-powered computers, to effect word sense disambiguation, and derive word senses across a large corpus of novels and poems. Here, too, I find that objects and other shapes become more common over this time period, although to less of an extent as with color. I explain this trend in conversation with thing theory and body theory, as bodies and body parts are a subset of things, in the lexical hierarchy I employ.
Finally, in Chapter 3, I synthesize these two facets of perception into the image, and trace the development of the textual image. Here, I train a neural network to recognize literary description, and find that, to my surprise, descriptive paragraphs largely decline in popularity over time. This makes it more difficult to explain the rise in visuality in this period, and so I turn to other contemporaneous movements, such as imagism and literary impressionism, to tell a story of the development of the literary eye.
Unlike the eye, however, the modernism of this dissertation’s title is much harder to delineate. I didn’t initially intend to study only modernist works, which would severely limit the scope of this study. Rather, most of the novels and collections of poems that appear at the tops of these lists are ones we tend to recognize as modernist, or as high modernist: James Joyce’s Ulysses and A Portrait of the Artist as a Young Man, Virginia Woolf’s Jacob’s Room and other novels, Katherine Mansfield’s short stories, and works by E.M. Forster, Ford Madox Ford, and other familiar figures. This makes it seem that the visuality I’m detecting here is not merely one of the moment, that is, of modernity, but of a modernism.
As with imagism and literary impressionism, though, I do not contend that modernism is a circumscribed school of thought with manifestos and static properties. Rather, I use these terms descriptively, to help explain the phenomena I detect, using well-discussed categories. The -ism suffix implies a kind of deliberate organization, or unifying ideology: a movement which aims towards a new kind of writing. By closely examining the theoretical writings of this period, I will show not only what happens, that is, the explosion of visuality around the turn of the century, but why and how it happens.
Thus, the contributions of this dissertation are three. The first, and most important, is methodological: I provide a method for modeling literary visuality which is the first of its kind in the field. Rather than simply count color words, as do many digital humanists, or object words, or even word vectors which represent these concepts, I provide a means of modeling the textual image which is based on ocular and cognitive processes. Divided into two parts, this method first quantifies color, by training computational models on color-word relations, and then, second, quantifies shapes, by leveraging state-of-the-art word-sense disambiguation models to identify objects, natural features, and other visual forms.
The second contribution is literary historical: I provide concrete data, the first of its kind, for how literary visuality has changed in British literature in the early twentieth century. Literary critics have long suspected what I show to be true quantitatively, but haven’t yet proven this suspicion with statistically significant evidence. I measure the rises and falls of each color, object, and visual attribute across this literary historical period.
The third is theoretical: rather than just show what happens with literary visuality, I show why and how. By drilling down into those passages which the model has identified as highly visual, or not visual at all, and by comparing generic and authorial metadata of these texts, I am able to derive theories for how this change in visuality takes place. From the invention of synthetic mauve dye in 1867, to art-historical trends like post-impressionism, and a renewed interest, among the modernists, for spatio-temporally distant art—Hellenic, Chinese, and others—I trace tendencies which, together, explain how the modernists began to see differently.
Background
In the famous preface to his 1897 novella The Nigger of the
Narcissus, Joseph Conrad announces that his project is, “by the
power of the written word, … to make you hear, to make you feel, …
before all, to make you see. That—and no more, and it is
everything.” I will argue that he means “seeing” more literally than we
usually suppose: not merely in the metaphorical sense of seeing as
understanding, but in the physiological sense, of seeing as a
neuro-ocular process. Conrad explains that his task is to hold up,
“before all eyes,” a “passing phase of life … to show its vibration, its
colour, its form, and through its movement, its form, and its colour,
reveal the substance of its truth” (Conrad
49). This trinity—color, form, and vibration/movement—is so
important to Conrad, or so conceptually slippery, that he allows it two
iterations, even in an essay that stresses the importance of verbal
economy. It is tempting to read these three words figuratively, to say
that “colour,” when describing “a passing phase of life” refers to an
affective experience, rather than a hue, and that “form” refers to a
conceptual structure, rather than the visual boundaries of physical
objects. That would not be entirely wrong. In fact, these, and more
esoteric readings, are among the most
typical.See, for example Enns and Trower (71). Ludwig Schnauder calls this
sequence a blend of “the terms and concepts of Impressionism with a
Victorian insistence on the truthfulness and moral sincerity of fiction”
(Schnauder 98).
But they overlook an an even more valuable reading, which
is yet more obvious: that color and form are physiologically
distinguishable ocular categories, corresponding to the rods and cones
of retinal photoreceptors, and that they depend on light (vibrations in
the visible electromagnetic spectrum) and a temporal dimension along
which their movements may be perceived.
These references to vision—again, real, not imagined vision—are abundant in this period, but are rarely treated literally. For example, here is Ford Madox Ford, writing about literary impressionism in 1939:
The main and perhaps most passionate tenet of impressionism was the suppression of the author from the pages of his book. He must not comment; he must not narrate; he must present his impressions of his imaginary affairs as if he had been present at them […] the author is invisible and almost unnoticeable and […] his attempt has been, above all, to make you see. (Ford 840)
Here, Ford has not only echoed Conrad’s dictum, but has gone further: the act of making the reader see, in the literary-impressionistic sense, is to erode the voice of the author and/or narrator, and convey sense impressions directly, rather than translate them through emotions, social niceties, rhetoric, or other intermediaries. Effectively, this is Woolf’s descriptive mode, rather than Austen’s. I will deal with literary impressionism later, in Chapter 1 and again in Chapter 3, but what is important to note now is just how directly we may encounter sight and vision, as they are understood by these writers.
The eye is more than just an adequate metaphor for the imagination of this period’s writers. To understand modernism, one must first understand the image, along with its primary interface, and first image-processing neural apparatus, the eye. The analyses in this dissertation presuppose a chain of perceptual processes that translate, with loss between each step, between object, image, and text.
This view of modernism is largely absent in contemporary scholarship,
although not absent from the greater archive of literary research. The
literary phenomena I’ll be analyzing here involve imagery, description,
and literary impression—all elements of fiction and poetry writing
which, although out of fashion as objects of study since the latter half
of the twentieth century, were some of the most-discussed topics in
literary theory of their
day.I chart exactly how these textual features have been
ignored, in Chapter 3. (See
also Ryf; Su; Goslee; Alldritt).
Despite some new trends, such as cognitive literary
criticism—a brand of literary analysis which approaches literary study
informed with recent findings in psychology and other cognitive
sciences—discussions of mental and textual imagery have all but fallen
silent since the 1950s. But what better ways to understand the artistic
work of the early twentieth century than through its own literary
theory?
One of these early theories of image in literature, to choose an illustrative example, is found in the work of I.A. Richards, a literary critic of the early twentieth century who was influential to the school of New Critics. In his Principles of Literary Criticism he diagrams the process of seeing, reading, and understanding a literary image, using a distinctly optical framework, as shown in fig. 1 (Richards 106).
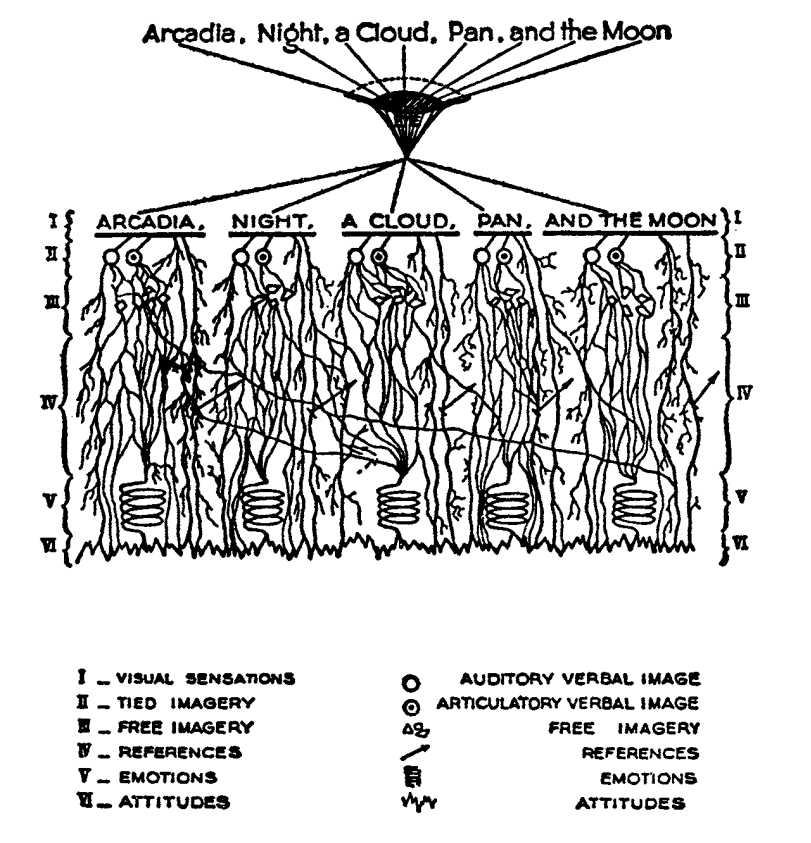
Richards explains that the six distinct processes depicted vertically here correspond to events happening in succession, through which these lines cross, as “streams of impulses flowing through in the mind” (113):
I. The visual sensations of the printed words.
II. Images very closely associated with these sensations.
III. Images relatively free.
IV. References to, or ‘thinkings of’, various things.
V. Emotions.
VI. Affective-volitional attitudes. (106-7)
Although Richards’s six-layer theory may read as old-fashioned to modern ears, perhaps more rooted in Richards’s imagination than science, it gives a sense of the complexity of the cognitive and emotional processes involved with reading words that bear visual significance. Not everyone produces mental images, but images that readers produce are amalgamations of memories, emotions, attitudes, and sensations. Crucially, they are optic at their very root. Consider the resemblance of Richards’s diagram to an illustration of retinal nerves, shown in Figure 2.
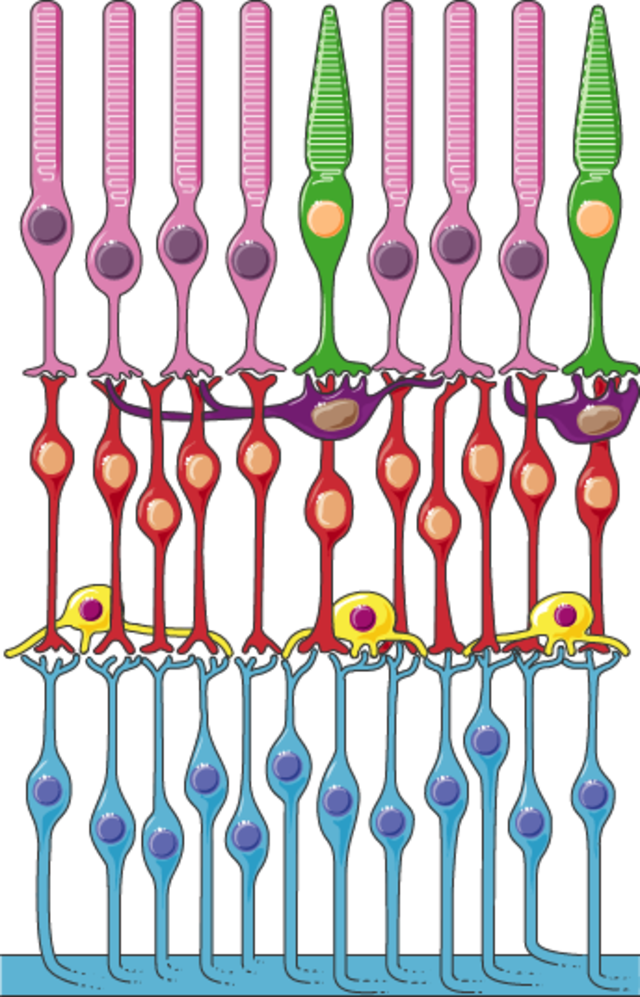
Richards, along with the modernists and imagists he studied, understood the reading process as a fundamentally visual one. The vision of the writer, then, is one which shapes a mental image into a textual one, to be later decoded by the reader. All of these processes are shaped and even controlled by the mechanisms of the eye.
Method
The methods I employ in this study blend quantitative and qualitative
criticism. While qualitative literary analysis is nothing new to
literary studies, quantitative criticism is relatively rare, and goes
under a variety of names. I largely use methods from computational
literary analysis, a field at the intersection of data science,
computational linguistics, and the sub-discipline of computer science
known as natural language processing. This is a practice of a
discipline, or disciplines, variously termed digital literary studies,
cultural analytics, or computational literary studies, and which falls
under a greater umbrella of digital
humanities.For digital literary studies, see Siemens and
Schreibman (; and Hoover et al.). For cultural
analytics, see The Journal
of Cultural Analytics. For computational literary studies,
see The Journal of Computational Literary
Studies.
In most cases, I will use computational rather than digital, for the work I’ll be doing in the following chapters, since information will be computed, rather than simply digitized, analyzed rather than simply stored. Similarly, I will use the term analysis rather than reading, which I feel unnecessarily anthropomorphizes the task. Franco Moretti, one of the field’s most-cited theorists, famously calls his practice “distant reading,” to contrast it with close reading, one of the most typical critical functions for literary scholars (Moretti). In his monograph of the same name, he outlines his logic:
“[T]he trouble with close reading (in all of its incarnations, from the new criticism to deconstruction) is that it necessarily depends on an extremely small canon. … [W]e know how to read texts, now let’s learn how not to read them. Distant reading: where distance, … is a condition of knowledge: it allows you to focus on units that are much smaller or much larger than the text: devices, themes, tropes—or genres and systems. And if, between the very small and the very large, the text itself disappears, well, it is one of those cases when one can justifiably say, Less is more.” (Moretti 49)
Moretti is not wrong that the scale or scope of an analysis determines its results, but the close/distant pair, is less mutually exclusive than it may seem from this polemic. In practice, close and distant reading complement each other perfectly: a large scale analysis of many hundreds or thousands of novels, like some of those I present in this dissertation, can identify works of literature outside the canon that have been ignored by critics, yet which stand in useful dialogue to canonical works and existing literary-theoretic discussions.
Ted Underwood also uses distant reading (Underwood); Matthew Jockers prefers “macroanalysis” (Jockers); Andrew Piper, in Enumerations studies quantitative aspects of literature through computational literary studies (Piper, Enumerations ). Ultimately, I do not pretend to create a new brand of literary criticism, but extend its existing methods with those of statistics and computer science. Much as the task that was once called computer-assisted design is now just design, there is a sense in which the technological aspects of these methods are not themselves innovations, but translations from existing humanistic ways of reading into computationally assisted reading.
Nearly every field of study eventually becomes data science, when enough data is involved: there will come a day in the biologists’s life when, after years of dissecting zebra fish, he needs to write a computer program to analyze all of his results. In the case of literature, we have been sitting on this data for decades, with relatively little exploration of it. I hope to correct that in the chapters that follow. This will involve analyzing a data set—a corpus of texts—using a variety of techniques, both of which I will now summarize.
Corpus
The problem of corpus creation was one of the most difficult problems I had to solve as a preliminary to the analyses of the following chapters. I wanted to limit my analysis to British literature of the 19th and 20th centuries, for several reasons. The first of which is the disciplinary divide which divides British literature into medieval, early modern, Victorian, and modernist camps: by limiting the scope of my analysis to these years, I can more cleanly engage with the scholarship which discusses this period. The Modern Language Association, for instance, divides its forums into categories such as “Late-18th-Century English,” “English Romantic,” “Victorian and Early-20th-Century English,” and “20th- and 21st-Century English and Anglophone” (MLA). These divisions aren’t arbitrary, but use different criteria in each: “Late-18th-Century” is a portion of a century; “English Romantic” is another such portion, but designated by its most prominent genre or era; “Victorian and Early-20th-Century” is both the only regnal era and the portion of a century that followed; and “20th- and 21st-Century English and Anglophone” suddenly includes all anglophone literature. I will be working roughly within the Victorian and early twentieth century periods, but with some differences: in order to show the explosion of color and shape in the 1880–1930 period, I often have to rewind to 1800, to provide the necessary context.
Another reason for choosing this period is more practical: spelling is relatively stable in these centuries than in prior periods. This same reason leads me to restrict my scope to British literature, rather than American, not only because this is my primary realm of expertise, but because the spelling and styles of these texts are more stable than in American texts. Furthermore, United States copyright law limits me to texts published before 1922, so while I will present charts that go up until 1930, the number of texts included beyond those years tends to fall off dramatically after 1922.
A further concern is that the twentieth century’s advances in international travel, communications, and publishing begin to blur the lines between English/British and other Anglophone literatures. Even in the early twentieth century, British literature is not so easy to define. The term as it is typically used includes the literatures of England, Wales, and Scotland, but often only those written in English, excluding Welsh, Scots, Scottish Gaelic, Cornish, and other languages of Great Britain. For practical reasons, I consider works of British literature, written in English.
What is British, geographically, however, is even more difficult to define. Depending on the time period, the designation includes works from the British empire. Prior to Irish independence, for instance, Ireland was considered British, by some, in some contexts. This is further confounded by the fact that many of the major figures of the British avant-garde were in fact American expatriates, living and and working in London. T.S. Eliot was born in Missouri, but moved to England at 25, where he lived for the rest of his life, eventually renouncing his American citizenship. Ezra Pound left America at 23, spending most of his life in England and on the continent, and wouldn’t return until facing trial for treason in the United States, and being committed to a mental institution. And Katherine Mansfield, a figure I will return to throughout, was an expatriate from New Zealand. These are not simple disparities to resolve, as we can rely on neither their legal nationality, nor their publishing history, nor even their own statements of national affinity.
So I needed a way to delineate British Literature, but since manually assembling a corpus would not only have been tedious, but impossible on the level of thousands of books, I also needed to compile a corpus programatically. For that, I turned to the Library of Congress classification, where the label PR denotes British Literature. There are many texts that are included in this classification that are surprising, and there are surprising omissions, as well. Mansfield’s works are usually classified as PR, Pound’s as PS (American literature), and Eliot’s, though he was legally and spiritually British, having joined the Church of England later in life, both PR and PS, depending. In the end, allowing the librarians to choose the boundaries of what is British freed me from hundreds of micro-decisions, such as whether James Joyce would’ve preferred to have been called British or Irish.
Years of corpus collecting, cleaning, and arranging led me to compile several large text repositories. The most notable of these was a virtually uncurated collection of about sixty thousand texts from the British Library, mostly from the nineteenth century. With participation from the members of the Literary Modeling and Visualization Lab, and several other volunteers, I started a project called Git-Lit to convert them from ALTO-XML, the format they were distributed in, clean them of OCR errors, and create version-controlled repositories for them, using the distributed version control system Git (Reeve, “Git-Lit”). I also experimented with compiling corpora by combining the English-language portion of the .txtLab Novel450 collection and the Corpus of English Novels, and by scraping sources outside the US, such as Project Gutenberg Australia (Piper, txtLab Novel450; De Smet). However, when combining corpora, inconsistencies between texts with different sources often lead to imbalanced results, which was especially undesirable for diachronic studies like the ones to follow.
One of the guiding concerns of this corpus creation process was the difference between canonical and archival texts. The “canon/archive” question is one which has been much discussed in recent years, especially due to the new prevalence of electronic texts. In computational literary analysis, this appears especially often, with three pamphlets of the Stanford Literary Lab on the subject, and several other studies of curricula, reading lists, and “classics” (Algee-Hewitt and McGurl; Algee-Hewitt et al.; Porter; González et al.; Walsh and Antoniak). The British Library texts were heavily archival, i.e., containing texts which have entirely been forgotten over the years; Project Gutenberg Australia and Canada texts were also heavily archival, containing Australiana and Canadiana which are of less interest to British literary-historical studies. While the arguments for exploring the so-called “great unread” of the archive are admirable, engaging with literary criticism at all would require work with canonical texts (Reid). Ultimately, I chose a single corpus, in order to have a consistent set of copyright restrictions, text quality, and other factors, and to balance works from both the canon and the archive.
My primary source of electronic texts then became Project Gutenberg, a repository of over 60,000 electronic texts, in operation since 1971 (Hart). The texts in Project Gutenberg were originally hand-keyed, i.e., manually entered into a computer, and proofread by a team known as Distributed Proofreaders. This allows the texts, in comparison to those generated via optical character recognition, or OCR, to be of relatively high quality, without textual errors that could confound statistical results.
Project Gutenberg contains a mix of canonical texts, like James Joyce’s Ulysses, with lesser-known texts, such as Richard Jefferies’s Round about a Great Estate, a work that will show up again and again in the chapters to come. While this has the effect of introducing texts that will be unknown and irrelevant to the average literary scholar, it also situates canonical texts within a larger tradition, and more importantly, within a generic milieu that teaches us more about the canonical works. My analysis of these “archival” works is not an attempt to rewrite the canon, by introducing new, ignored works, but to expand our understanding of the canonical works. Even if we have never seen or heard of Jefferies’s book, to know it as a work of rural nature writing with a keen eye for detail will help to illuminate why it is so often found clustered with other detailed novels such as Ulysses.
One major drawback of Project Gutenberg, however, is that the
metadata for its texts are not as complete as with other text
repositories. Each text has metadata fields for title and author, a
Project Gutenberg “bookshelf”, a Library of Congress class, or category,
a Library of Congress subject heading, and the date of its publication
on Project Gutenberg. One missing field—one which would be the most
useful field for computational literary history—is the date of original
publication. To find this, I had to devise a method for augmenting
Project Gutenberg metadata with information from other public data
repositories. To accomplish that, I created a database and API called Corpus-DB, which aggregates electronic
texts from Project Gutenberg and other repositories, and augments their
metadata using several external sources (Reeve, “Corpus-DB”). I
developed this project over the course of several years, with the help
of a few students and other volunteers. To augment the metadata, I used
the title and author of the texts to create SPARQL queries to query
the graph knowledge databases such as DBPedia and Wikidata (Auer et al.; Lehmann et al.;
Vrandečić; Vrandečić and
Krötzsch). Both dictionary-based knowledge graphs, these
databases maintain statements in the form of triples, e.g.,
<Ulysses> <first published> <1922>. A
SPARQL query could then ask the database engine to solve for date of
first publication, given the title and author of a text.
The problem with this approach, though, is that it can only find these data for books which already have a Wikipedia article or entry within a larger article. That severely limits the number of books, to 1,647, or, the total number of books from Project Gutenberg, from the Library of Congress classification PR, originally written in English, which have Wikipedia articles that also name their dates of original publication, and which were first published between 1800 and 1922. This corpus I’ll be calling \(C_{PG2}\). A subset of that corpus which starts later, for the purpose of zooming in on the 1880–1930 era, I’ll call \(C_{PG}\).
I also gleaned some additional book data from APIs from Amazon, Goodreads, and Open Library. In those cases where metadata diverged, for example when there were different publication dates, I developed an algorithm to guess the best one (usually the earliest). From this process, I was able to find several thousand texts and associate them with their publication dates. From there, I also did some basic deduplication, using document embeddings to guess duplicate texts.
Technologies
I developed four independent software programs for this project, as well as a large number of scripts for analytic tasks, using the Python and Haskell programming languages, among others. The four main programs, which are included in this repository as submodules, are as follows:
- color-word-analyzer: a CLI program and web app to analyze color in a text, for Chapter 1
- custom-ngrams-search: a framework for searching Google NGrams data for custom textual patterns, for Chapter 1
- count-objects: software for counting objects in literary texts, using word sense disambiguation, for Chapter 2
- description-detection: a program for probabilistically detecting literary description, for Chapter 3
Each of these programs are usable by readers or third parties, and
are accompanied with documentation that explain their usage. Each is
also accompanied with the inclusion of reproducible build programs in
the Nix language which ensure that these programs will be executable for
years to come
For the use of the Nix package manager for
reproducibility in science, see Devresse et al.
.
The text of this dissertation itself, too, is the product of a non-trivial amount of programming. What you are reading is a richly-formatted, interactive document, presented in HTML, and using JavaScript libraries for interactivity. I made the unconventional decision to produce this dissertation in HTML, rather than produce a Microsoft Word document or a PDF file, to take advantage of recent advances in web publishing.
There is a growing trend of so-called “digital dissertations” which use interactive features, and produce documents that are less linear than usual (Fox). But the “digital” designation is becoming increasingly meaningless, since PDFs and Word documents, as much as they mimic paper, are still digital. Still, as much as this is a digital dissertation, I hope that it is not a novelty, or merely an experiment in form, but an literary-critical argument which happens to take advantage of some of the more recent textual technologies.
Since Word and PDF were created as proprietary formats, developed by Microsoft and Adobe, they were made to sell software, rather than contribute to the community. Furthermore, they are made to mimic the paper office, using a virtual 8.5 by 11 inch “page.” Since this dissertation will not be printed, this constraint is unnecessary. HTML, on the other hand, is much more featureful markup language, allowing for interactive charts, hyperlinks, variable page width, and much, much more. Since it it always-already published on the Internet, it is much more easily archivable, readable with a wider variety of reading software (web browsers), and provides a more seamless experience for those using screen readers or other accessibility software.
One of the most important features of this HTML format is the capability to embed interactive charts. An interactive chart, like some of the scatter plots I present in Chapter 1, allow the reader the ability to see which texts account for the overall diachronic trends, by hovering the mouse pointer over a point, or selecting a range of points by dragging the mouse over a region.
This text is originally written in a feature-rich markup language called Org, which compiles to HTML. The software stack that transforms the source code into its final version contains a number of innovations:
- A Shakefile written in Haskell, for the Shake build system, which interfaces with Pandoc to convert plain text files to HTML, which I originally wrote in the org-mode text format.
- A template written in Lucid and Clay, Haskell domain-specific languages for HTML and CSS, which integrates Tufte-CSS, Mermaid diagram capability, and more.
- Custom Pandoc filters, written in Haskell: one for displaying color hex values, used in Chapter 1, and one for displaying WordNet synsets, used in Chapter 2.
- Semantic tagging, using the Schema.org Thesis ontology.
This technological stack I’ve then abstracted into the template project template-dissertation, a standards-focused, HTML-first dissertation build system, so that it can be used by others.
How to Read This Dissertation
Some words of encouragement may be of use for readers of this dissertation. The first chapter, on color, will spend considerable time explaining the experimental design: the mechanisms of the text-to-color inference, the formulas used for color difference calculation. Framing that will be a lengthy discussion of the epistemological difficulties of color in text, from Wittgenstein to dye manufacturing to phenomenology. One or another of these tactics will, to readers of varying backgrounds and interests, seem like unimportant details. But to those who are tempted to skip anything resembling an equation, I challenge you to consider it a differently-written literary-critical argument. To those who are inclined to skip the more speculative, philosophical discussions, I challenge you to consider it a differently-worded algorithm.
The following chapter, on objects, will attempt to interface between the structures of hierarchical lexical databases and the relatively new sub-field of literary object study. Again, these are both crucial aspects of my argument, which posits that both are illuminated by reading one in terms of the other. Readers who have never encountered lexical databases will doubtless find their history to be irrelevant to object study, and those familiar with them may find object theory to be too broad and airy, compared to the real work of sense disambiguation. I invite all readers to consider these paired tactics to be mutually amplifying translations of one another.
The third and final chapter considers a network of several factors which help to explain the visual phenomena I discover across literary history of this period: literary impressionism, imagism, and various movements in the visual arts, to name a few. These are accompanied with an experiment which measures description in fiction and poetry. The results of the experiment are reflected, however faint it may seem, in the literary movements I discuss. Although I emphasize, at various points, the interconnected nature of the phenomena which I detect and the literary movements that comprise them, it will help to keep this in mind while reading.
In the end, the the algorithm is the criticism, and the criticism is the algorithm. I invite you to consider both as ways of reading.